AlphaGo新演算法仍有一大弱點 柯潔不要被它嚇倒
[文/觀察者網專欄作者 陳經]
2016年12月29日至2017年1月4日,谷歌AlphaGo的升級版本以Master為名,在弈城圍
棋網和野狐圍棋網的快棋比賽中對人類最高水準的選手取得了60:0的壓倒戰績,再次讓
人們對圍棋AI的實力感到震驚。
之前《自然》論文對AlphaGo的演算法進行了非常細緻的介紹,世界各地不少研發團
隊根據這個論文進行了圍棋AI的開發。其中進展最大的應該是騰訊開發的 “刑天”(以
及之前的版本“絕藝”),職業棋手和棋迷們感覺它的實力達到了2016年3月與李世石對
戰的AlphaGo版本。但是經過近一年的升級,Master的實力顯然比之前版本要強得多,它
背後的演算法演變成什麼樣了,卻幾乎沒有資料。本文對AlphaGo的升級後的演算法框架
進行深入的分析與 猜測,試圖從電腦演算法角度揭開它的神秘面紗一角。
在1月4日AlphaGo團隊的正式聲明中,Deepmind提到了“our new prototype version
(我們新的原型版本)”。prototype這個詞在軟體工程領域一般對應一個新的演算法框
架,並不是簡單的性能升級,可能是演算法原理級的改 變。由於資料極少,我只能根據
很少的一些資訊,以及Master的實戰表現對此進行分析與猜測。
下文中,我們將2015年10月戰勝樊麾二段的AlphaGo版本稱為V13,將2016年3月戰勝
李世石的版本稱為V18,將升級後在網路上60:0戰勝人類高手群體的版本稱為V25(這個
版本Deepmind內部應該有不同的稱呼)。
V13與V25:從廖化到關羽
版本V13的戰績是,正式的慢棋5:0勝樊麾,棋譜公佈了,非正式的快棋3:2勝樊麾
,棋譜未公佈。樊麾非正式快棋勝了兩局,這說明版本V13的快棋實力並不是太強。
版本V18的戰績是,每方2小時3次1分鐘讀秒的慢棋,以4:1勝李世石。比賽中
AlphaGo以非常穩定的1分鐘1步的節奏下棋。比賽用的分散式機器有1202個CPU和176個GPU
,據說每下一局光電費就要3000美元。
版本V25的戰績是,Master以60:0戰勝30多位人類棋手,包括排名前20位的所有棋手
。比賽大部分是3次30秒讀秒的快棋,開始10多局人們關 注不多時是20秒讀秒用時更短,
僅有一次60秒讀秒是照顧年過六旬的聶衛平。比賽中Master每步幾乎都在8秒以內落子,
從未用掉過讀秒(除了一次意外掉線),所以20秒或者30秒對機器是一回事。在KGS上天
元開局三局虐殺ZEN的GodMoves很可能也是版本V25,這三局也是快棋,GodMoves每步都是
幾秒,用時只有ZEN的一半。
可以看出,版本V13的快棋實力不強。而版本V18的快棋實力應該也不如慢棋,谷歌為
了確保勝利,用了分散式的版本而非48個CPU與8個GPU的單機版,還用了每步1分鐘這種
在AI中算多的每步用時。在比賽中,有時AlphaGo的剩餘用時甚至比李世石少了。應該說
這時的AlphaGo版本有堆機器提升棋力的感覺,和IBM在1997年與卡斯帕羅夫的國際象棋
人機大戰時的做法類似。
但是版本V25在比賽用時上進步很大,每步8秒比版本V18快了六七倍,而棋力卻提升
很大。柯潔與朴廷桓在30秒用時的比賽中能多次戰勝與版本V18實力 相當的刑天,同樣的
用時對Master幾盤中卻毫無機會。應該說版本V25在用時大大減少的同時還取得了棋力巨
大的進步,這是雙重的進步,一定是因為演算法 原理有了突破,絕對不是靠提升機器性
能。而這與國際像棋AI的進步過程有些類似。
IBM在人機大戰中戰勝卡斯帕羅夫後解散了團隊不玩了,但其它研究者繼續開發國際
象棋AI取得了巨大的進步。後來演算法越做越厲害,最厲害的程式能讓人類最高水準的棋
手一個兵或者兩先。水準極高的國際象棋AI不少,其中一個是鱈魚(stockfish),由許
多開發者集體開發,攻殺淩厲,受到愛好者追捧。
另一個是變色龍(Komodo),由一個國際象棋大師和一個程式師開發,理論體系嚴謹
,攻防穩健。AI互相對局比人類多得多,二者對下100盤,變色龍以 9勝89平2負領先人氣
高的鱈魚。因為AI在平常的手機上都可以戰勝人類最高水準的棋手,國際象棋(以及類似
的中國象棋)都禁止棋手使用手機,曾經有棋手 頻繁上廁所看手機被抓禁賽。國際象棋
AI在棋力以及計算性能上都取得了巨大的進步,運算平臺從特別造的大型伺服器移到了人
人都有的手機上。
局面評估函數的作用
從演算法上來說,高水準國際象棋AI的關鍵是人工植入的一些國際象棋相關的領域知
識,加上傳統的電腦搜索高效剪枝演算法。值得注意的是,AlphaGo以及之前所有高水準
AI如ZEN和CrazyStone都採用MCTS(蒙特卡洛樹形搜索),而最高水準的國際象棋AI是不
用的。MCTS是 CrazyStone的作者法國人Remi Coulom 在2006年最先提出的,是上一次圍
棋人工智慧演算法取得巨大進步能夠戰勝一般業餘棋手的關鍵技術突破。
但MCTS其實是傳統搜索技術沒有辦法解決圍棋問題時,想出來的變通辦法,並不是說
它比傳統搜索技術更先進。實際MCTS隨機模擬,並不是太嚴謹,它是成千上萬次模擬,
每次模擬都下至終局數子確定勝負統計各種選擇的勝率。這是一個對人類棋手來說相當不
自然的方法,可以預期人類絕對不會用這種辦法去下棋。
國際象棋也可以用MCTS去做,但沒有必要。谷歌團隊有人用深度學習和MCTS做了國際
象棋程式,但是棋力僅僅是國際大師,並沒有特別厲害。高水準國際象棋演算法的核心技
術,是極為精細的“局面評估函數”。而這早在幾十年前,就是人工智慧博弈演算法的核
心問題。國際象棋的局面評估函數很好理解,基本想法是對皇后、車、馬、象、兵根據戰
鬥力大小給出不同的分值,對王給出一個超級大的分值死了就是最差的局面。一個局面就
是棋子的分值和。
但這只是最原始的想法,子力的搭配、兵陣的形狀、棋子的位置更為關鍵,象棋中的
棄子攻殺極為常見。這需要國際象棋專業人士進行極為專業細緻的估值調整。國際象棋
AI的水準高低基本由它的局面評估函數決定。有了好用的局面評估函數以後,再以此為基
礎,展開一個你一步我一步的指數擴展的博弈搜尋樹。在這個搜索樹上,利用每個局面
計算出來的分值,進行一些專業的高效率“剪枝”(如Alpha-Beta剪枝演算法)操作,縮
小樹的規模,用有限的計算資源盡可能地搜索 更多的棋步,又不發生漏算。
圖為搜尋樹示例,方塊和圓圈是兩個對手,每一條線代表下出一招。局面評估後,棋手
要遵守MIN-MAX的原則,要“誠實”地認為對手能下出最強應對再去想自己的招。有局面
評估分數的葉子節點其實不用都搜索到,因為理論上有剪枝演算法證明不用搜索了。如一
下被人吃掉一個大子,又得不到補償的分枝就不用繼續往下推了。這些搜索技術發展到
很複雜了,但都屬於傳統的搜索技術,是人可以信服的邏輯。
國際象棋與中國象棋AI發展到水準很高後,棋手們真的感覺到了電腦的深不可測,就
是有時電腦會下出人類難於理解的“AI棋”。人類對手互相下,出了招以後,人就會想
對手這是想幹什麼,水準相當的對手仔細思考後總是能發現對手的戰術意圖,如設個套雙
吃對手的馬和車,如果對手防著了,就能吃個兵。而“AI 棋”的特徵是,它背後並不是
一條或者少數幾條戰術意圖,而是有一個龐大的搜尋樹支持,人類對手作出任何應對,它
都能在幾手、十幾手後占得優勢,整個戰略並 不能用幾句話解釋清楚,可能需要寫一篇
幾千字的文章。
這種“AI棋”要思考非常周密深遠,人類選手很難下出來。近年來中國象棋成績最好
的是王天一,他的棋藝特點就是主動用軟體進行訓練,和上一輩高手方法不同。王天一
下出來的招有時就象AI,以致于有些高手風言風語影射他用軟體作弊引發風波,我認為應
該是訓練方法不同導致的。國際象棋界對軟體的重視與應用比 中國象棋界要強得多,重
大比賽時,一堆人用軟體分析雙方的著手好壞,直接作為判據,增加了比賽的可看性。
軟體能下出“AI棋”,是因為經過硬體以及演算法的持續提升,程式的搜索能力終於
突破了人類的腦力限制,經過高效剪枝後,幾千萬次搜索可以連續推理多步並覆蓋各個分
枝,在深度與廣度方面都超過人類,可以說搜索能力已經超過人類。
其實最初的圍棋AI也是用這個思路開發的,也是建立搜尋樹,在葉子節點上搞局面評
估函數計算。但是圍棋的評估函數特別難搞,初級的程式一般用黑白子對周邊空點的“
控制力”之類的原始邏輯進行估值,差錯特別大,估值極為離譜,棋力極低。無論怎麼人
工加調整,也搞不好,各種棋形實在是太複雜。很長時間圍棋AI 沒有實質進步,受限於
評估函數極差的能力,搜索能力極差。
實在是沒有辦法了,才搞出MCTS這種非自然的隨機下至終局統計勝率的辦法。MCTS部
分解決了估值精確性問題,因為下到終局數子是準確的,只要模擬的次數足夠多,有理
論證明可以逼近最優解。用這種變通的辦法繞開了局面評估這個博弈搜索的核心問題。以
此為基礎,以ZEN為代表的幾個程式,在根據棋形走子選點上下了苦功,終於取得了棋力
突破,能夠戰勝一般業餘棋手。
接下來自然的發展就是用深度學習對人類高手的選點直覺建模,就是“策略網路”。
這次突破引入了機器學習技術,不需要開發者辛苦寫代碼了,高水準圍棋AI的開發變容
易了。即使這樣,由於評估函數沒有取得突破,仍然需要MCTS來進行勝率統計,棋力仍然
受限,只相當於業餘高手。
“價值網路”橫空出世
AlphaGo在局面評估函數上作出了嘗試性的創新,用深度學習技術開發出了“價值網
路”。它的特點是,局面評分也是勝率,而不是領先多少目這種較為自然的優勢計算。
但是從《自然》論文以及版本V13與V18的表現來看,這時的價值網路並不是太準確,不能
單獨使用,應 該是一個經常出錯的函數。論文中提到,葉子節點勝率評估是把價值網路
和MCTS下至終局混合使用,各占0.5權重。這個意思是說,AlphaGo會象國際 象棋搜索演
算法一樣,展開一個葉子節點很多的樹。
在葉子節點上,用價值網路算出一個勝率,再從葉子節點開始黑白雙方一直輪流走子
終局得出勝負。兩者都要參考,0.5是一個經驗性的資料,這樣棋力最高。這 其實是一個
權宜之計,價值網路會出錯,類比走子終局也並不可靠,通過混合想互相彌補一下,但並
不能解決太多問題。最終棋力還是需要靠MCTS海量類比試 錯,模擬到新的關鍵分枝提升
棋力。所以版本V18特別需要海量計算,每步需要的時間相對長,需要的CPU與GPU個數也
不少,谷歌甚至開發了特別的TPU 進行深度神經網路平行計算提高計算速度。
整個《自然》論文給人的感覺是,AlphaGo在圍棋AI的工程實施的各個環節都精益求
精做到最好,最後的棋力並不能簡單地歸因於一兩個技術突破。演算法研發與軟體工程
硬體開發多個環節都不計成本地投入,需要一個人數不小的精英團隊全力支援,也需要大
公司的財力與硬體支援。V13與V18更多給人的感覺是工程成就,之前的圍棋AI開發者基
本是兩三個人的小團隊小成本開發,提出了各式各樣的演算法思想,AlphaGo來了個集大
成,終於取得了棋力突破。
即使這樣,V18在實戰中也表現出了明顯缺陷,輸給李世石一局,也出了一些局部計
算錯誤。如果與國際象棋AI的表現對比,對人並不能說有優勢,而是各有所長。人類高手
熟悉這類圍棋AI的特點後,勝率會上升,正如對騰訊AI刑天與絕藝的表現。
ZEN、刑天、AlphaGo版本V18共同的特點是大局觀很好。連ZEN的大局觀都超過一些不
太注意大局的職業棋手,但是戰鬥力不足。這是MCTS海量類比至終局精確數目帶來的優
勢,對於地塊的價值估計比人要准。它們共同的弱點也是局部戰鬥中會出問題,死活搞不
清,棋力高的問題少點。這雖然出乎職業棋手的預料,從演算法角度看是自然的。海量
終局模擬能體現虛虛的大局觀,但是這類圍棋AI的“搜索能力”仍然是不足的,局面評估
函數水準不高,搜索能力就不足, 或者看似搜得深但有漏洞。正是因為搜索能力不足,
才需要用MCTS來主打。
但是AlphaGo的價值網路是一個非常重要而且有巨大潛力的技術。它的革命性在於,
用機器學習的辦法去解決局面評估函數問題,避免了開發者自己去寫難度極大甚至是不可
能寫出來的高水準圍棋局面評估函數。國際象棋開發者可以把評估思想寫進代碼裡,圍棋
是不可能的,過去的經驗已經證明了這一點。機器學習的優點是,把人類說不清楚的複雜
邏輯放在多達幾百M的多層神經網路係數裡,通過海量的大資料把這些係數訓練出來。
給定一個圍棋局面,誰占優是有確定答案的,高手也能講出一些道理,有內在的邏輯
。這是一個標準的人工智慧監督學習問題,它的難度在於,由於深度神經網路結構複雜
係數極多,需要的訓練樣本數量極大,而高水準圍棋對局的資料更加難於獲取。Deepmind
是通過機器自我對局,積累了2000萬局高品質對局作為訓練樣本,這個投入是海量的,
如果機器數量不多可能要幾百年時間,短期生成這麼多棋局動用的伺服器多達十幾萬台。
但如果真的有了這個條件,那麼研究就是開放的,怎麼準備海量樣本,如何構建價值網
路的多層神經網路,如何訓練提升評估品質,可以去想辦法。
AlphaGo團隊演算法負責人David Silver在2016年中的一次學術報告會上說,團隊又
取得了巨大進步,新版本可以讓V18四個子了,主要是價值網路取得了巨大進步。這是非
常重要的資訊。
V25能讓V18四個子,如果V18相當於人類最高水準的棋手,這是不可想像的。根據
Master對人類60局棋來看,讓四子是絕對不可能的,讓二子人類高手們都有信心。我猜
測,V18是和V25下快棋才四個子還輸的。AlphaGo的訓練與評估流水線中,機器自我對局
是下快棋,每步5秒這樣。2016年9月還公佈了三局自我對局棋譜,就是這樣下出來的。
V18的快棋能力差,V25在價值網路取得巨大進步能力後,搜索能力上升極大,只要幾秒的
時間,搜索質量就足夠了。為什麼價值網路的巨大進步帶來的好處這麼大?
如果有了一個比V18要靠譜得多的價值網路,就等於初步解決了局面評估函數問題。
這樣,AlphaGo新的prototype就更接近于傳統的以局面評估 為核心的搜索框架,帶有確
定性質的搜索就成為演算法能力的主要力量,碰運氣的MCTS不用主打了。因此,V25對人
類高手的實戰表現,可以與高水準國際象棋 AI相當了。
我可以肯定V25的搜索框架會給價值網路一個很高的權重(如0.9),只給走子至終局
數子很低的權重。如果局面平穩雙方展開圈地運動,那麼各局面的價值網 絡分值差不多
,MCTS模擬至終局的大局觀會起作用。如果發生局部戰鬥,那麼價值網路就會起到主導作
用,對戰鬥分枝的多個選擇,價值網路都迅速給出明快的判斷,通過較為完整的搜索展開
,象國際象棋AI一樣論證出人類棋手看不懂的“AI棋”。
http://n.sinaimg.cn/sports/crawl/20170110/j4zJ-fxzkfvn1218631.jpg
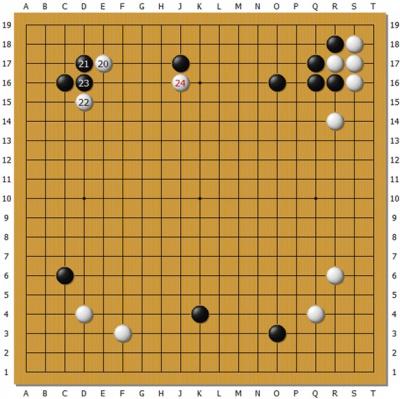
上圖為Master執白對陳耀燁。在黑子力占優的左上方,白20掛入,黑21尖頂奪白根據地
意圖整體攻擊,白22飛靈活轉身是常型,23團準備切斷白,這時Master忽然在24位靠黑
一子。Master比起之前的版本V18,感覺行棋要積極一些,對人類棋手的考驗也更多。可
以想見這裡黑內扳外扳兩邊長脫 先各種應法很多,並不是很容易判斷。
但是如果有價值網路對各個結果進行準確估值,Master可能在下24的時候就已經給出
了結論,黑無論如何應,白棋都局勢不錯。陳耀燁自戰解說認為,24這招他已經應不好了
,實戰只好委屈地先穩住陣腳,複盤也沒有給出好的應對。同樣的招法Master對朴廷桓也
下過。
http://n.sinaimg.cn/sports/crawl/20170110/iSPW-fxzkfuk3297663.jpg
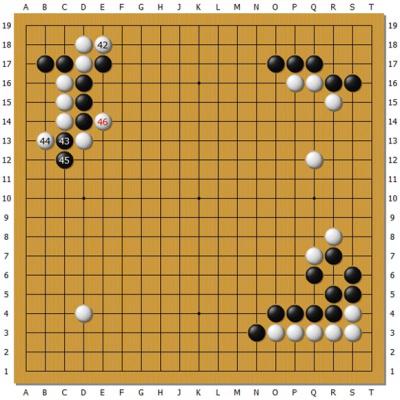
上圖為Master執白對羋昱廷,左上角的大雪崩外拐定式,白下出新手。白44職業棋手都是
走在E13長的,後續變化很複雜。但是Master卻先44打 一下,下了讓所有人都感到震驚的
46扳,在這個古老的定式下出了從未見過的新手。這個新手讓羋昱廷短時間內應錯了,吃
了大虧。後來羋昱廷自戰回顧時說應該可以比實戰下得好些,黑棋能夠厚實很多,但也難
說占優。但是對白46這招還沒有完全接受。這個局面很複雜,有多個要點,Master的搜索
中是完全沒有定 式的概念的。
我猜測它會各種手段都試下,由於價值網路比過去精確了,可以建立一個比較龐大的
搜尋樹,然後象國際象棋AI一樣多個局面都考慮過之後綜合出這個新手。這次 Master表
現得不怕複雜變化,而之前版本感覺上是進行大局掌控,複雜變化算不清繞開去。Master
卻經常主動挑起複雜變化,明顯感覺搜索能力有進步,算路要深了。
局面評估函數精確到一定程度突破了臨界點,就可以帶來搜索能力的巨大進步。因為
開發者可以放心地利用局面評估函數進行高效率的剪枝,節省出來的計算能力可以用於更
深的推導,表現出來就是算得深算得廣。實際人類的剪枝能力是非常強大的,計算速度太
慢,如果還要去思考一些明顯不行的分枝,根本沒辦法進行細緻的推理。在一個局面人類
的推理,其實就是一堆變化圖,眾多高手可能就取得一致意見了。而Master以及國際象棋
AI也是走這個路線了,它們能擺多得多的變化圖,足以覆蓋人類考慮到的那些變化圖給出
靠譜的結論。
但這個路線的必須依靠足夠精確的價值網路,否則會受到多種干擾。一是估值錯了,
好局面扔掉壞局面留著選錯棋招。二是剪枝不敢做,搜索大量無意義的局面,有意義的局
面沒時間做或者深度不足。三是要在葉子節點引入快速走子下完的“驗證”,這種驗證未
必靠譜,價值網路正確的估值反而給帶歪了。
從實戰表現反推,Master的價值網路品質肯定已經突破了臨界點,帶來了極大的好處
,思考時間大幅減少,搜索深度廣度增加,戰鬥力上升。AlphaGo團隊新的prototype,
架構上可能更簡單了,需要的CPU數目也減少了,更接近國際象棋的搜索框架,而不是以
MCTS為基礎的複雜框架。比起國際象 棋AI複雜的人工精心編寫的局面評估函數,AlphaGo
的價值網路完全由機器學習生成,編碼任務更為簡單。
理論上來說,如果價值網路的估值足夠精確,可以將葉子節點價值網路的權重上升為
1.0,就等於在搜索框架中完全去除了MCTS模組,和傳統搜索演算法完全一 樣了。這時的
圍棋AI將從理論上完全戰勝人,因為人能做的機器都能做,而且還做得更好更快。而圍棋
AI的發展過程可以簡略為兩個階段。第一階段局面估值函 數能力極弱,被逼引入MCTS以
及它的天生弱點。第二階段價值網路取得突破,再次將MCTS從搜索框架逐漸去除返朴歸真
,回歸傳統搜索演算法。
由於價值網路是一個機器學習出來的黑箱子,人類很難理解裡面是什麼,它的能力會
到什麼程度不好說。這樣訓練肯定會碰到瓶頸,再也沒法提升了,但版本V18那時顯然沒
到瓶頸,之後繼續取得了巨大進步。通常機器學習是模仿人的能力,如人臉識別、語音辨
識的能力超過人。但是圍棋局面評估可以說是對人與機器來說都 非常困難的任務。
職業棋手們的常識是,直線計算或者計算更周密是可以努力解決的有客觀標準的問題
,但是局面判斷是最難的,說不太清楚,棋手們的意見並不統一。由於人的局 評估能
力並不太高,Master的價值網路在幾千萬對局巧妙訓練後超過人類是可以想像的,也帶來
了棋力與用時表現的巨大進步。但是可以合理推測,AlphaGo團隊也不太可能訓練無缺陷
的價值網路,不太可能訓練出國際象棋AI那種幾乎完美的局面評估函數。
我的猜測是,Master現在是一個“自信”的棋手,並不像之前版本那樣對搜索沒信心
靠海量模擬至終局驗算。它充分相信自己的價值網路,以此為基礎短時間內展開龐大的搜
尋樹,下出信心十足算路深遠的“AI棋”,對人類棋手主動挑起戰鬥。這個姿態它是有了
。但是它這個“自信”並不是真理,它只是堅定地這樣判斷了。肯定有一些局面它的評估
有誤差,如圍棋之神說是白勝的,Master認為是黑勝。人類棋手需要找到它的推理背後的
錯誤,與之進行判斷的較量,不能被它嚇倒。
http://n.sinaimg.cn/sports/crawl/20170110/d8Ib-fxzkfuh6523669.jpg
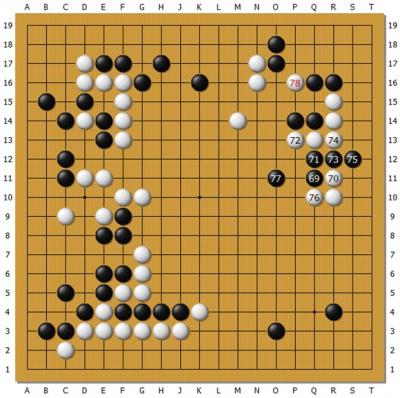
上圖是Master執黑對孟泰齡。本局下得較早,Master雖然連勝但沒有戰勝太多強手,孟
泰齡之前有戰勝絕藝的經驗,心理較為穩定並不怕它,本局發揮不錯。Master黑69點入,
71、73、75將白棋分為兩段發起兇猛的攻擊。但是孟泰齡下出78位元靠的好手,局部結果
如下圖。
http://n.sinaimg.cn/sports/crawl/20170110/rxaD-fxzkfuk3297669.jpg
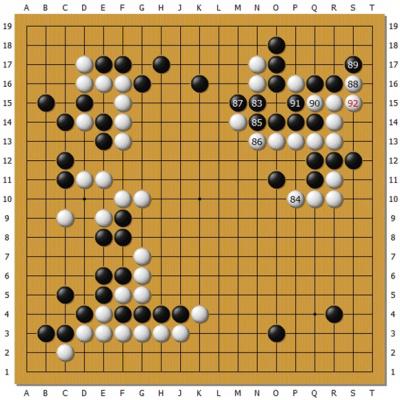
黑棋右邊中間分斷白棋的四子已經被吃,白棋厚勢與左下勢力形成呼應,右上還有R17
斷吃角部一子的大官子。黑棋只吃掉了白棋上邊兩子,這兩子本就處於受攻狀態白並不想
要。這個結果無論如何應該是白棋獲利,Master發生了誤算,或者局面評估失誤。
現在職業棋手與AlphaGo團隊的棋藝競爭態勢可能是這樣的。AlphaGo不再靠MCTS主導
搜索改而以價值網路主打,思考時間大大縮短,在10秒以內就達到了極高棋力,之後時間
再長棋力增長也並不多。棋力主要是由價值網路的品質決定的,堆積伺服器增加搜索時間
對搜索深度廣度意義並不太大。所以Master已經較充分的展示了實力,並不是說還有棋力
強大很多的版本。這和國際象棋AI類似,兩個高水準AI短時間就能大戰100局,並不需要
人類那麼長的思考時間。
Master的60局快棋擊中了人類棋藝的弱點,它極為自信地主動發起挑戰敢於導入複雜
局面,而人類高手卻沒有能力在30秒內完善應對這些不太熟悉的新手。而這些新手並不
是簡單的新型,背後有Master的價值網路支援的龐大搜尋樹。如果價值網路的這些估值是
準確的,人類高手即使完美應對,也只能是不吃虧,犯錯就會被佔便宜。有些局面下,
價值網路的估計會有誤差,這時人類高手有懲罰Master的機會,但需要充足的時間思考,
也要有足夠的自信與 Master的判斷進行較量。這次60局中棋手由於用時太短心態失衡很
少做到,一般還是會吃虧。
以下是我對柯潔與AlphaGo的人機大戰的建議:
1。 要對機器有足夠瞭解,不要盲目猜測。可以簡單的理解,它接近一個以價值網路
為基礎的傳統搜索程式。
2。 要相信機器並不完美。如果它的局面評估函數沒有錯誤了,或者遠遠超過人,那
就和國際象棋AI一樣不可戰勝了。但圍棋足夠複雜,即使是幾千萬局的深度學習,也不可
能訓練出特別好的價值網路,一定會有漏洞與誤差。只是因為人的局面評估也不是太好,
才顯得機器很厲害。
3。 這次機器會堅定而自信地出手,它改變了風格,在局面仍然膠著的時候不會回避
複雜變化。因為它的搜索深度廣度增加了,它認為自己算清了,堅定出手維護自己的判斷
,甚至會主動撲劫造劫。
4。 機器的退讓是在勝定的情況下,它認為反正是100%獲勝了,就隨機選了一手。後
半盤出現這種情況不用太費勁去思考了,應該保留體力迅速下完,下一局再戰鬥。
5。 機器的大局觀仍然會很好,基於多次模擬數空,對於虛空的估計從原理上就比人強
,這方面人要頂住但不能指望靠此獲勝。還是應該在複雜局部中與機器進行戰鬥,利用機
器價值網路的估值失誤,以人對局面估計的自信與機器的自信進行比拼。機器是自信的,
人類也必須自信。也許機器評估正確的概率更大,但是既然都不完美,人類也可能在一些
局面判斷更為正確。
6。 機器對稍複雜戰鬥局面的評估是有龐大搜尋樹支持的,並不會發生簡單的漏算,
不應該指望找到簡單的手段給機器毀滅性打擊。由於人類的思考速度慢,時間有限,不能
進行太全面的思考。應該集中思考自己判斷不錯的局面,圍繞它進行論證。如果這個判斷
正好是人類正確、機器錯誤,那人是有機會占優的。
通過以上分析,我對人機大戰柯潔勝出一局甚至更多局還是抱有一定期望的。希望柯
潔能夠總結分析圍棋AI的技術特點,增加自信,針鋒相對採取正確的戰略,捍衛人類的圍
棋價值觀。
http://sports.sina.com.cn/go/2017-01-10/doc-ifxzkfuk3300666.shtml
--
[文/觀察者網專欄作者 陳經]
2016年12月29日至2017年1月4日,谷歌AlphaGo的升級版本以Master為名,在弈城圍
棋網和野狐圍棋網的快棋比賽中對人類最高水準的選手取得了60:0的壓倒戰績,再次讓
人們對圍棋AI的實力感到震驚。
之前《自然》論文對AlphaGo的演算法進行了非常細緻的介紹,世界各地不少研發團
隊根據這個論文進行了圍棋AI的開發。其中進展最大的應該是騰訊開發的 “刑天”(以
及之前的版本“絕藝”),職業棋手和棋迷們感覺它的實力達到了2016年3月與李世石對
戰的AlphaGo版本。但是經過近一年的升級,Master的實力顯然比之前版本要強得多,它
背後的演算法演變成什麼樣了,卻幾乎沒有資料。本文對AlphaGo的升級後的演算法框架
進行深入的分析與 猜測,試圖從電腦演算法角度揭開它的神秘面紗一角。
在1月4日AlphaGo團隊的正式聲明中,Deepmind提到了“our new prototype version
(我們新的原型版本)”。prototype這個詞在軟體工程領域一般對應一個新的演算法框
架,並不是簡單的性能升級,可能是演算法原理級的改 變。由於資料極少,我只能根據
很少的一些資訊,以及Master的實戰表現對此進行分析與猜測。
下文中,我們將2015年10月戰勝樊麾二段的AlphaGo版本稱為V13,將2016年3月戰勝
李世石的版本稱為V18,將升級後在網路上60:0戰勝人類高手群體的版本稱為V25(這個
版本Deepmind內部應該有不同的稱呼)。
V13與V25:從廖化到關羽
版本V13的戰績是,正式的慢棋5:0勝樊麾,棋譜公佈了,非正式的快棋3:2勝樊麾
,棋譜未公佈。樊麾非正式快棋勝了兩局,這說明版本V13的快棋實力並不是太強。
版本V18的戰績是,每方2小時3次1分鐘讀秒的慢棋,以4:1勝李世石。比賽中
AlphaGo以非常穩定的1分鐘1步的節奏下棋。比賽用的分散式機器有1202個CPU和176個GPU
,據說每下一局光電費就要3000美元。
版本V25的戰績是,Master以60:0戰勝30多位人類棋手,包括排名前20位的所有棋手
。比賽大部分是3次30秒讀秒的快棋,開始10多局人們關 注不多時是20秒讀秒用時更短,
僅有一次60秒讀秒是照顧年過六旬的聶衛平。比賽中Master每步幾乎都在8秒以內落子,
從未用掉過讀秒(除了一次意外掉線),所以20秒或者30秒對機器是一回事。在KGS上天
元開局三局虐殺ZEN的GodMoves很可能也是版本V25,這三局也是快棋,GodMoves每步都是
幾秒,用時只有ZEN的一半。
可以看出,版本V13的快棋實力不強。而版本V18的快棋實力應該也不如慢棋,谷歌為
了確保勝利,用了分散式的版本而非48個CPU與8個GPU的單機版,還用了每步1分鐘這種
在AI中算多的每步用時。在比賽中,有時AlphaGo的剩餘用時甚至比李世石少了。應該說
這時的AlphaGo版本有堆機器提升棋力的感覺,和IBM在1997年與卡斯帕羅夫的國際象棋
人機大戰時的做法類似。
但是版本V25在比賽用時上進步很大,每步8秒比版本V18快了六七倍,而棋力卻提升
很大。柯潔與朴廷桓在30秒用時的比賽中能多次戰勝與版本V18實力 相當的刑天,同樣的
用時對Master幾盤中卻毫無機會。應該說版本V25在用時大大減少的同時還取得了棋力巨
大的進步,這是雙重的進步,一定是因為演算法 原理有了突破,絕對不是靠提升機器性
能。而這與國際像棋AI的進步過程有些類似。
IBM在人機大戰中戰勝卡斯帕羅夫後解散了團隊不玩了,但其它研究者繼續開發國際
象棋AI取得了巨大的進步。後來演算法越做越厲害,最厲害的程式能讓人類最高水準的棋
手一個兵或者兩先。水準極高的國際象棋AI不少,其中一個是鱈魚(stockfish),由許
多開發者集體開發,攻殺淩厲,受到愛好者追捧。
另一個是變色龍(Komodo),由一個國際象棋大師和一個程式師開發,理論體系嚴謹
,攻防穩健。AI互相對局比人類多得多,二者對下100盤,變色龍以 9勝89平2負領先人氣
高的鱈魚。因為AI在平常的手機上都可以戰勝人類最高水準的棋手,國際象棋(以及類似
的中國象棋)都禁止棋手使用手機,曾經有棋手 頻繁上廁所看手機被抓禁賽。國際象棋
AI在棋力以及計算性能上都取得了巨大的進步,運算平臺從特別造的大型伺服器移到了人
人都有的手機上。
局面評估函數的作用
從演算法上來說,高水準國際象棋AI的關鍵是人工植入的一些國際象棋相關的領域知
識,加上傳統的電腦搜索高效剪枝演算法。值得注意的是,AlphaGo以及之前所有高水準
AI如ZEN和CrazyStone都採用MCTS(蒙特卡洛樹形搜索),而最高水準的國際象棋AI是不
用的。MCTS是 CrazyStone的作者法國人Remi Coulom 在2006年最先提出的,是上一次圍
棋人工智慧演算法取得巨大進步能夠戰勝一般業餘棋手的關鍵技術突破。
但MCTS其實是傳統搜索技術沒有辦法解決圍棋問題時,想出來的變通辦法,並不是說
它比傳統搜索技術更先進。實際MCTS隨機模擬,並不是太嚴謹,它是成千上萬次模擬,
每次模擬都下至終局數子確定勝負統計各種選擇的勝率。這是一個對人類棋手來說相當不
自然的方法,可以預期人類絕對不會用這種辦法去下棋。
國際象棋也可以用MCTS去做,但沒有必要。谷歌團隊有人用深度學習和MCTS做了國際
象棋程式,但是棋力僅僅是國際大師,並沒有特別厲害。高水準國際象棋演算法的核心技
術,是極為精細的“局面評估函數”。而這早在幾十年前,就是人工智慧博弈演算法的核
心問題。國際象棋的局面評估函數很好理解,基本想法是對皇后、車、馬、象、兵根據戰
鬥力大小給出不同的分值,對王給出一個超級大的分值死了就是最差的局面。一個局面就
是棋子的分值和。
但這只是最原始的想法,子力的搭配、兵陣的形狀、棋子的位置更為關鍵,象棋中的
棄子攻殺極為常見。這需要國際象棋專業人士進行極為專業細緻的估值調整。國際象棋
AI的水準高低基本由它的局面評估函數決定。有了好用的局面評估函數以後,再以此為基
礎,展開一個你一步我一步的指數擴展的博弈搜尋樹。在這個搜索樹上,利用每個局面
計算出來的分值,進行一些專業的高效率“剪枝”(如Alpha-Beta剪枝演算法)操作,縮
小樹的規模,用有限的計算資源盡可能地搜索 更多的棋步,又不發生漏算。
圖為搜尋樹示例,方塊和圓圈是兩個對手,每一條線代表下出一招。局面評估後,棋手
要遵守MIN-MAX的原則,要“誠實”地認為對手能下出最強應對再去想自己的招。有局面
評估分數的葉子節點其實不用都搜索到,因為理論上有剪枝演算法證明不用搜索了。如一
下被人吃掉一個大子,又得不到補償的分枝就不用繼續往下推了。這些搜索技術發展到
很複雜了,但都屬於傳統的搜索技術,是人可以信服的邏輯。
國際象棋與中國象棋AI發展到水準很高後,棋手們真的感覺到了電腦的深不可測,就
是有時電腦會下出人類難於理解的“AI棋”。人類對手互相下,出了招以後,人就會想
對手這是想幹什麼,水準相當的對手仔細思考後總是能發現對手的戰術意圖,如設個套雙
吃對手的馬和車,如果對手防著了,就能吃個兵。而“AI 棋”的特徵是,它背後並不是
一條或者少數幾條戰術意圖,而是有一個龐大的搜尋樹支持,人類對手作出任何應對,它
都能在幾手、十幾手後占得優勢,整個戰略並 不能用幾句話解釋清楚,可能需要寫一篇
幾千字的文章。
這種“AI棋”要思考非常周密深遠,人類選手很難下出來。近年來中國象棋成績最好
的是王天一,他的棋藝特點就是主動用軟體進行訓練,和上一輩高手方法不同。王天一
下出來的招有時就象AI,以致于有些高手風言風語影射他用軟體作弊引發風波,我認為應
該是訓練方法不同導致的。國際象棋界對軟體的重視與應用比 中國象棋界要強得多,重
大比賽時,一堆人用軟體分析雙方的著手好壞,直接作為判據,增加了比賽的可看性。
軟體能下出“AI棋”,是因為經過硬體以及演算法的持續提升,程式的搜索能力終於
突破了人類的腦力限制,經過高效剪枝後,幾千萬次搜索可以連續推理多步並覆蓋各個分
枝,在深度與廣度方面都超過人類,可以說搜索能力已經超過人類。
其實最初的圍棋AI也是用這個思路開發的,也是建立搜尋樹,在葉子節點上搞局面評
估函數計算。但是圍棋的評估函數特別難搞,初級的程式一般用黑白子對周邊空點的“
控制力”之類的原始邏輯進行估值,差錯特別大,估值極為離譜,棋力極低。無論怎麼人
工加調整,也搞不好,各種棋形實在是太複雜。很長時間圍棋AI 沒有實質進步,受限於
評估函數極差的能力,搜索能力極差。
實在是沒有辦法了,才搞出MCTS這種非自然的隨機下至終局統計勝率的辦法。MCTS部
分解決了估值精確性問題,因為下到終局數子是準確的,只要模擬的次數足夠多,有理
論證明可以逼近最優解。用這種變通的辦法繞開了局面評估這個博弈搜索的核心問題。以
此為基礎,以ZEN為代表的幾個程式,在根據棋形走子選點上下了苦功,終於取得了棋力
突破,能夠戰勝一般業餘棋手。
接下來自然的發展就是用深度學習對人類高手的選點直覺建模,就是“策略網路”。
這次突破引入了機器學習技術,不需要開發者辛苦寫代碼了,高水準圍棋AI的開發變容
易了。即使這樣,由於評估函數沒有取得突破,仍然需要MCTS來進行勝率統計,棋力仍然
受限,只相當於業餘高手。
“價值網路”橫空出世
AlphaGo在局面評估函數上作出了嘗試性的創新,用深度學習技術開發出了“價值網
路”。它的特點是,局面評分也是勝率,而不是領先多少目這種較為自然的優勢計算。
但是從《自然》論文以及版本V13與V18的表現來看,這時的價值網路並不是太準確,不能
單獨使用,應 該是一個經常出錯的函數。論文中提到,葉子節點勝率評估是把價值網路
和MCTS下至終局混合使用,各占0.5權重。這個意思是說,AlphaGo會象國際 象棋搜索演
算法一樣,展開一個葉子節點很多的樹。
在葉子節點上,用價值網路算出一個勝率,再從葉子節點開始黑白雙方一直輪流走子
終局得出勝負。兩者都要參考,0.5是一個經驗性的資料,這樣棋力最高。這 其實是一個
權宜之計,價值網路會出錯,類比走子終局也並不可靠,通過混合想互相彌補一下,但並
不能解決太多問題。最終棋力還是需要靠MCTS海量類比試 錯,模擬到新的關鍵分枝提升
棋力。所以版本V18特別需要海量計算,每步需要的時間相對長,需要的CPU與GPU個數也
不少,谷歌甚至開發了特別的TPU 進行深度神經網路平行計算提高計算速度。
整個《自然》論文給人的感覺是,AlphaGo在圍棋AI的工程實施的各個環節都精益求
精做到最好,最後的棋力並不能簡單地歸因於一兩個技術突破。演算法研發與軟體工程
硬體開發多個環節都不計成本地投入,需要一個人數不小的精英團隊全力支援,也需要大
公司的財力與硬體支援。V13與V18更多給人的感覺是工程成就,之前的圍棋AI開發者基
本是兩三個人的小團隊小成本開發,提出了各式各樣的演算法思想,AlphaGo來了個集大
成,終於取得了棋力突破。
即使這樣,V18在實戰中也表現出了明顯缺陷,輸給李世石一局,也出了一些局部計
算錯誤。如果與國際象棋AI的表現對比,對人並不能說有優勢,而是各有所長。人類高手
熟悉這類圍棋AI的特點後,勝率會上升,正如對騰訊AI刑天與絕藝的表現。
ZEN、刑天、AlphaGo版本V18共同的特點是大局觀很好。連ZEN的大局觀都超過一些不
太注意大局的職業棋手,但是戰鬥力不足。這是MCTS海量類比至終局精確數目帶來的優
勢,對於地塊的價值估計比人要准。它們共同的弱點也是局部戰鬥中會出問題,死活搞不
清,棋力高的問題少點。這雖然出乎職業棋手的預料,從演算法角度看是自然的。海量
終局模擬能體現虛虛的大局觀,但是這類圍棋AI的“搜索能力”仍然是不足的,局面評估
函數水準不高,搜索能力就不足, 或者看似搜得深但有漏洞。正是因為搜索能力不足,
才需要用MCTS來主打。
但是AlphaGo的價值網路是一個非常重要而且有巨大潛力的技術。它的革命性在於,
用機器學習的辦法去解決局面評估函數問題,避免了開發者自己去寫難度極大甚至是不可
能寫出來的高水準圍棋局面評估函數。國際象棋開發者可以把評估思想寫進代碼裡,圍棋
是不可能的,過去的經驗已經證明了這一點。機器學習的優點是,把人類說不清楚的複雜
邏輯放在多達幾百M的多層神經網路係數裡,通過海量的大資料把這些係數訓練出來。
給定一個圍棋局面,誰占優是有確定答案的,高手也能講出一些道理,有內在的邏輯
。這是一個標準的人工智慧監督學習問題,它的難度在於,由於深度神經網路結構複雜
係數極多,需要的訓練樣本數量極大,而高水準圍棋對局的資料更加難於獲取。Deepmind
是通過機器自我對局,積累了2000萬局高品質對局作為訓練樣本,這個投入是海量的,
如果機器數量不多可能要幾百年時間,短期生成這麼多棋局動用的伺服器多達十幾萬台。
但如果真的有了這個條件,那麼研究就是開放的,怎麼準備海量樣本,如何構建價值網
路的多層神經網路,如何訓練提升評估品質,可以去想辦法。
AlphaGo團隊演算法負責人David Silver在2016年中的一次學術報告會上說,團隊又
取得了巨大進步,新版本可以讓V18四個子了,主要是價值網路取得了巨大進步。這是非
常重要的資訊。
V25能讓V18四個子,如果V18相當於人類最高水準的棋手,這是不可想像的。根據
Master對人類60局棋來看,讓四子是絕對不可能的,讓二子人類高手們都有信心。我猜
測,V18是和V25下快棋才四個子還輸的。AlphaGo的訓練與評估流水線中,機器自我對局
是下快棋,每步5秒這樣。2016年9月還公佈了三局自我對局棋譜,就是這樣下出來的。
V18的快棋能力差,V25在價值網路取得巨大進步能力後,搜索能力上升極大,只要幾秒的
時間,搜索質量就足夠了。為什麼價值網路的巨大進步帶來的好處這麼大?
如果有了一個比V18要靠譜得多的價值網路,就等於初步解決了局面評估函數問題。
這樣,AlphaGo新的prototype就更接近于傳統的以局面評估 為核心的搜索框架,帶有確
定性質的搜索就成為演算法能力的主要力量,碰運氣的MCTS不用主打了。因此,V25對人
類高手的實戰表現,可以與高水準國際象棋 AI相當了。
我可以肯定V25的搜索框架會給價值網路一個很高的權重(如0.9),只給走子至終局
數子很低的權重。如果局面平穩雙方展開圈地運動,那麼各局面的價值網 絡分值差不多
,MCTS模擬至終局的大局觀會起作用。如果發生局部戰鬥,那麼價值網路就會起到主導作
用,對戰鬥分枝的多個選擇,價值網路都迅速給出明快的判斷,通過較為完整的搜索展開
,象國際象棋AI一樣論證出人類棋手看不懂的“AI棋”。
http://n.sinaimg.cn/sports/crawl/20170110/j4zJ-fxzkfvn1218631.jpg
上圖為Master執白對陳耀燁。在黑子力占優的左上方,白20掛入,黑21尖頂奪白根據地
意圖整體攻擊,白22飛靈活轉身是常型,23團準備切斷白,這時Master忽然在24位靠黑
一子。Master比起之前的版本V18,感覺行棋要積極一些,對人類棋手的考驗也更多。可
以想見這裡黑內扳外扳兩邊長脫 先各種應法很多,並不是很容易判斷。
但是如果有價值網路對各個結果進行準確估值,Master可能在下24的時候就已經給出
了結論,黑無論如何應,白棋都局勢不錯。陳耀燁自戰解說認為,24這招他已經應不好了
,實戰只好委屈地先穩住陣腳,複盤也沒有給出好的應對。同樣的招法Master對朴廷桓也
下過。
http://n.sinaimg.cn/sports/crawl/20170110/iSPW-fxzkfuk3297663.jpg
上圖為Master執白對羋昱廷,左上角的大雪崩外拐定式,白下出新手。白44職業棋手都是
走在E13長的,後續變化很複雜。但是Master卻先44打 一下,下了讓所有人都感到震驚的
46扳,在這個古老的定式下出了從未見過的新手。這個新手讓羋昱廷短時間內應錯了,吃
了大虧。後來羋昱廷自戰回顧時說應該可以比實戰下得好些,黑棋能夠厚實很多,但也難
說占優。但是對白46這招還沒有完全接受。這個局面很複雜,有多個要點,Master的搜索
中是完全沒有定 式的概念的。
我猜測它會各種手段都試下,由於價值網路比過去精確了,可以建立一個比較龐大的
搜尋樹,然後象國際象棋AI一樣多個局面都考慮過之後綜合出這個新手。這次 Master表
現得不怕複雜變化,而之前版本感覺上是進行大局掌控,複雜變化算不清繞開去。Master
卻經常主動挑起複雜變化,明顯感覺搜索能力有進步,算路要深了。
局面評估函數精確到一定程度突破了臨界點,就可以帶來搜索能力的巨大進步。因為
開發者可以放心地利用局面評估函數進行高效率的剪枝,節省出來的計算能力可以用於更
深的推導,表現出來就是算得深算得廣。實際人類的剪枝能力是非常強大的,計算速度太
慢,如果還要去思考一些明顯不行的分枝,根本沒辦法進行細緻的推理。在一個局面人類
的推理,其實就是一堆變化圖,眾多高手可能就取得一致意見了。而Master以及國際象棋
AI也是走這個路線了,它們能擺多得多的變化圖,足以覆蓋人類考慮到的那些變化圖給出
靠譜的結論。
但這個路線的必須依靠足夠精確的價值網路,否則會受到多種干擾。一是估值錯了,
好局面扔掉壞局面留著選錯棋招。二是剪枝不敢做,搜索大量無意義的局面,有意義的局
面沒時間做或者深度不足。三是要在葉子節點引入快速走子下完的“驗證”,這種驗證未
必靠譜,價值網路正確的估值反而給帶歪了。
從實戰表現反推,Master的價值網路品質肯定已經突破了臨界點,帶來了極大的好處
,思考時間大幅減少,搜索深度廣度增加,戰鬥力上升。AlphaGo團隊新的prototype,
架構上可能更簡單了,需要的CPU數目也減少了,更接近國際象棋的搜索框架,而不是以
MCTS為基礎的複雜框架。比起國際象 棋AI複雜的人工精心編寫的局面評估函數,AlphaGo
的價值網路完全由機器學習生成,編碼任務更為簡單。
理論上來說,如果價值網路的估值足夠精確,可以將葉子節點價值網路的權重上升為
1.0,就等於在搜索框架中完全去除了MCTS模組,和傳統搜索演算法完全一 樣了。這時的
圍棋AI將從理論上完全戰勝人,因為人能做的機器都能做,而且還做得更好更快。而圍棋
AI的發展過程可以簡略為兩個階段。第一階段局面估值函 數能力極弱,被逼引入MCTS以
及它的天生弱點。第二階段價值網路取得突破,再次將MCTS從搜索框架逐漸去除返朴歸真
,回歸傳統搜索演算法。
由於價值網路是一個機器學習出來的黑箱子,人類很難理解裡面是什麼,它的能力會
到什麼程度不好說。這樣訓練肯定會碰到瓶頸,再也沒法提升了,但版本V18那時顯然沒
到瓶頸,之後繼續取得了巨大進步。通常機器學習是模仿人的能力,如人臉識別、語音辨
識的能力超過人。但是圍棋局面評估可以說是對人與機器來說都 非常困難的任務。
職業棋手們的常識是,直線計算或者計算更周密是可以努力解決的有客觀標準的問題
,但是局面判斷是最難的,說不太清楚,棋手們的意見並不統一。由於人的局 評估能
力並不太高,Master的價值網路在幾千萬對局巧妙訓練後超過人類是可以想像的,也帶來
了棋力與用時表現的巨大進步。但是可以合理推測,AlphaGo團隊也不太可能訓練無缺陷
的價值網路,不太可能訓練出國際象棋AI那種幾乎完美的局面評估函數。
我的猜測是,Master現在是一個“自信”的棋手,並不像之前版本那樣對搜索沒信心
靠海量模擬至終局驗算。它充分相信自己的價值網路,以此為基礎短時間內展開龐大的搜
尋樹,下出信心十足算路深遠的“AI棋”,對人類棋手主動挑起戰鬥。這個姿態它是有了
。但是它這個“自信”並不是真理,它只是堅定地這樣判斷了。肯定有一些局面它的評估
有誤差,如圍棋之神說是白勝的,Master認為是黑勝。人類棋手需要找到它的推理背後的
錯誤,與之進行判斷的較量,不能被它嚇倒。
http://n.sinaimg.cn/sports/crawl/20170110/d8Ib-fxzkfuh6523669.jpg
上圖是Master執黑對孟泰齡。本局下得較早,Master雖然連勝但沒有戰勝太多強手,孟
泰齡之前有戰勝絕藝的經驗,心理較為穩定並不怕它,本局發揮不錯。Master黑69點入,
71、73、75將白棋分為兩段發起兇猛的攻擊。但是孟泰齡下出78位元靠的好手,局部結果
如下圖。
http://n.sinaimg.cn/sports/crawl/20170110/rxaD-fxzkfuk3297669.jpg
黑棋右邊中間分斷白棋的四子已經被吃,白棋厚勢與左下勢力形成呼應,右上還有R17
斷吃角部一子的大官子。黑棋只吃掉了白棋上邊兩子,這兩子本就處於受攻狀態白並不想
要。這個結果無論如何應該是白棋獲利,Master發生了誤算,或者局面評估失誤。
現在職業棋手與AlphaGo團隊的棋藝競爭態勢可能是這樣的。AlphaGo不再靠MCTS主導
搜索改而以價值網路主打,思考時間大大縮短,在10秒以內就達到了極高棋力,之後時間
再長棋力增長也並不多。棋力主要是由價值網路的品質決定的,堆積伺服器增加搜索時間
對搜索深度廣度意義並不太大。所以Master已經較充分的展示了實力,並不是說還有棋力
強大很多的版本。這和國際象棋AI類似,兩個高水準AI短時間就能大戰100局,並不需要
人類那麼長的思考時間。
Master的60局快棋擊中了人類棋藝的弱點,它極為自信地主動發起挑戰敢於導入複雜
局面,而人類高手卻沒有能力在30秒內完善應對這些不太熟悉的新手。而這些新手並不
是簡單的新型,背後有Master的價值網路支援的龐大搜尋樹。如果價值網路的這些估值是
準確的,人類高手即使完美應對,也只能是不吃虧,犯錯就會被佔便宜。有些局面下,
價值網路的估計會有誤差,這時人類高手有懲罰Master的機會,但需要充足的時間思考,
也要有足夠的自信與 Master的判斷進行較量。這次60局中棋手由於用時太短心態失衡很
少做到,一般還是會吃虧。
以下是我對柯潔與AlphaGo的人機大戰的建議:
1。 要對機器有足夠瞭解,不要盲目猜測。可以簡單的理解,它接近一個以價值網路
為基礎的傳統搜索程式。
2。 要相信機器並不完美。如果它的局面評估函數沒有錯誤了,或者遠遠超過人,那
就和國際象棋AI一樣不可戰勝了。但圍棋足夠複雜,即使是幾千萬局的深度學習,也不可
能訓練出特別好的價值網路,一定會有漏洞與誤差。只是因為人的局面評估也不是太好,
才顯得機器很厲害。
3。 這次機器會堅定而自信地出手,它改變了風格,在局面仍然膠著的時候不會回避
複雜變化。因為它的搜索深度廣度增加了,它認為自己算清了,堅定出手維護自己的判斷
,甚至會主動撲劫造劫。
4。 機器的退讓是在勝定的情況下,它認為反正是100%獲勝了,就隨機選了一手。後
半盤出現這種情況不用太費勁去思考了,應該保留體力迅速下完,下一局再戰鬥。
5。 機器的大局觀仍然會很好,基於多次模擬數空,對於虛空的估計從原理上就比人強
,這方面人要頂住但不能指望靠此獲勝。還是應該在複雜局部中與機器進行戰鬥,利用機
器價值網路的估值失誤,以人對局面估計的自信與機器的自信進行比拼。機器是自信的,
人類也必須自信。也許機器評估正確的概率更大,但是既然都不完美,人類也可能在一些
局面判斷更為正確。
6。 機器對稍複雜戰鬥局面的評估是有龐大搜尋樹支持的,並不會發生簡單的漏算,
不應該指望找到簡單的手段給機器毀滅性打擊。由於人類的思考速度慢,時間有限,不能
進行太全面的思考。應該集中思考自己判斷不錯的局面,圍繞它進行論證。如果這個判斷
正好是人類正確、機器錯誤,那人是有機會占優的。
通過以上分析,我對人機大戰柯潔勝出一局甚至更多局還是抱有一定期望的。希望柯
潔能夠總結分析圍棋AI的技術特點,增加自信,針鋒相對採取正確的戰略,捍衛人類的圍
棋價值觀。
http://sports.sina.com.cn/go/2017-01-10/doc-ifxzkfuk3300666.shtml
--
All Comments